



final_score = (0.2 × render_score) +
(0.1 × keyword_matching) +
(0.7 × vqa_score)
 StructEval
StructEval
As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs' capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: (1) generation tasks, producing structured output from natural language prompts, and (2) conversion tasks, translating between structured formats.
Our benchmark encompasses 18 formats and 44 types of tasks, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps—even state-of-the-art models like o1-mini achieve only 75.58% average score, with open-source alternatives lagging approximately 10 points behind. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.
StructEval comprises 2,035 examples covering 44 unique structure generation tasks across 18 structured output formats. The dataset is organized into two main subsets:
Evaluates text-only structured outputs
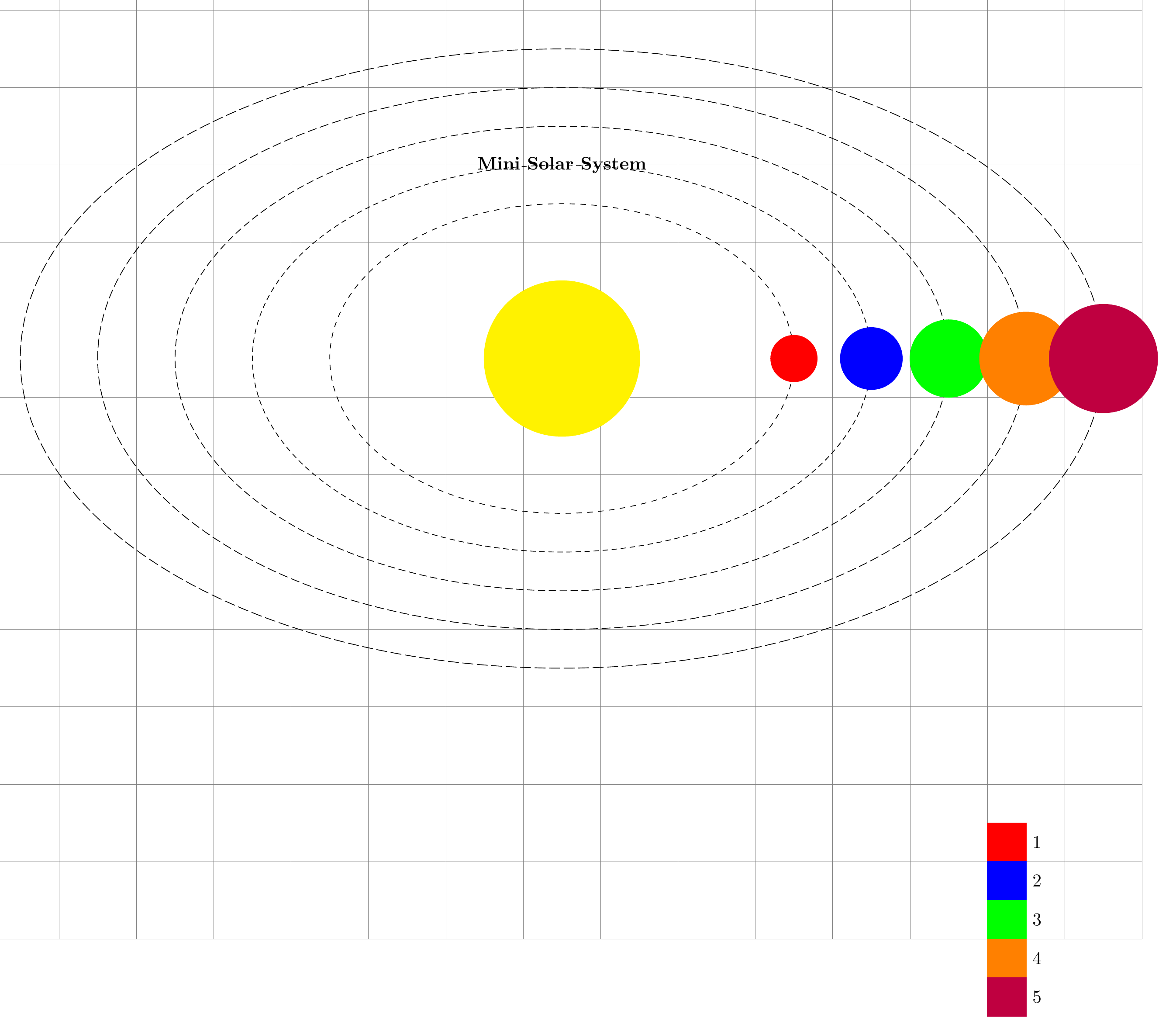
Evaluates visually rendered outputs
Please output JSON code. Task: Summarize metadata about a fictional scientific article. Feature Requirements: 1. Top-level field "title" is a string 2. Field "authors" is a list of exactly two items 3. Each author has "name" and "affiliation" 4. Field "publication.year" is an integer 5. Field "keywords" is a list of strings
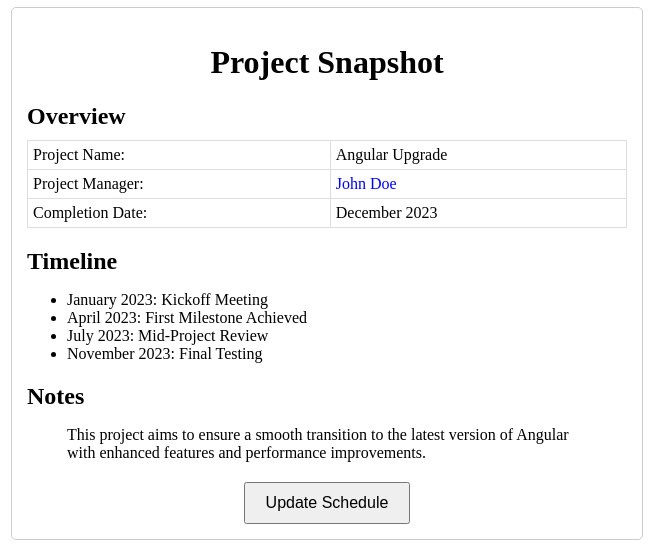
titleauthors[0].nameauthors[1].affiliationpublication.yearkeywords[2]Please output HTML code. Task: Design a webpage for a travel itinerary. Feature Requirements: • Centered <h1> with "Trip Summary" • Use a <table> with 3 rows and 2 columns • Apply class "highlight" to second row • Add <button> labeled "Export PDF"
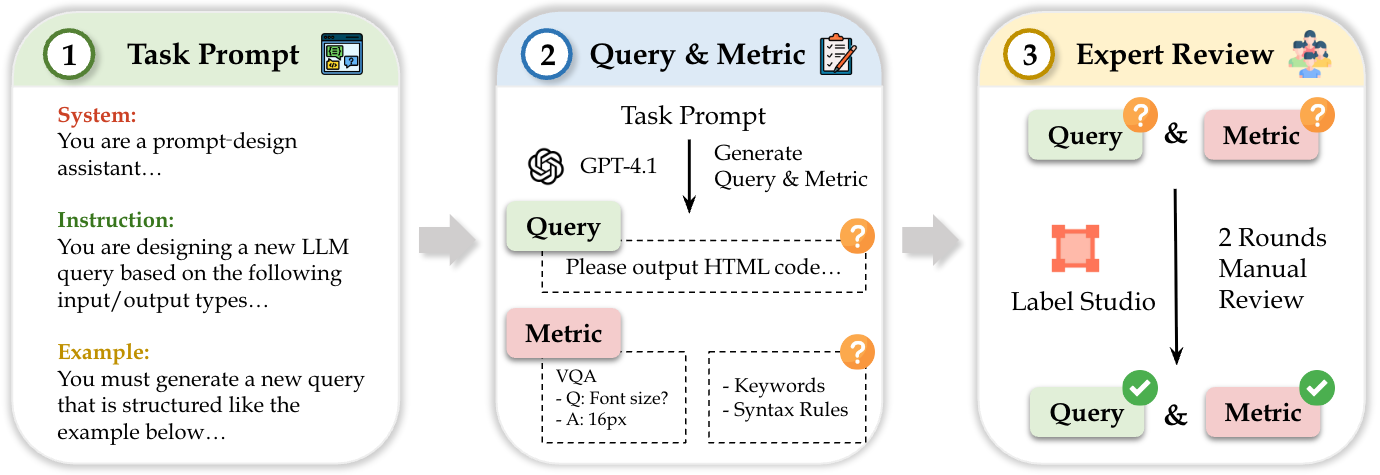
Our evaluation framework employs four core metrics:
Measures the percentage of generated code that can be successfully loaded or rendered into images
Verifies structural correctness using format-specific parsers or rendering engines
Evaluates presence of required structural elements using path-based rules
Assesses visual correctness through GPT-4V-based question answering (V tasks only)
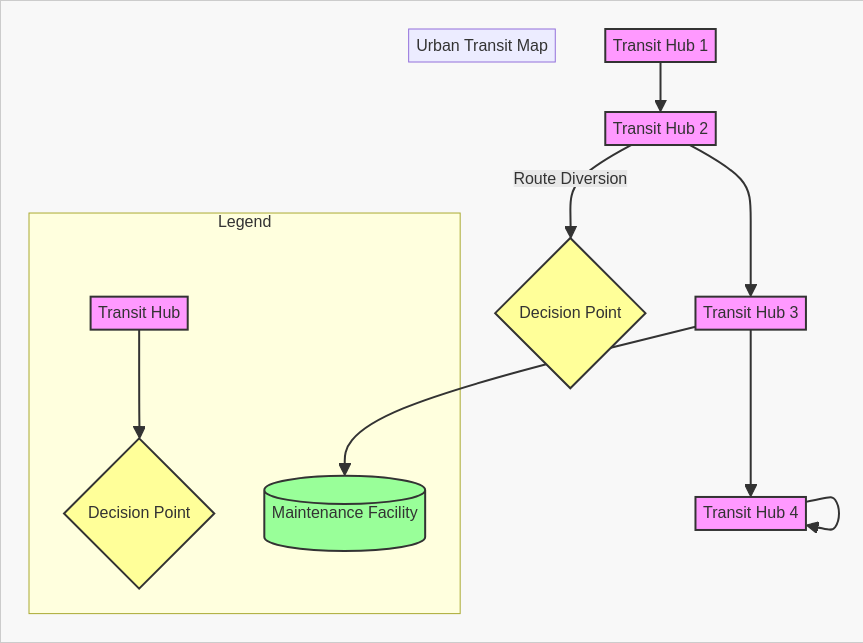
HTML, React, SVG, LaTeX, Mermaid, etc.
final_score = (0.2 × render_score) +
(0.1 × keyword_matching) +
(0.7 × vqa_score)
JSON, XML, YAML, CSV, TOML
final_score = (0.2 × render_score) +
(0.8 × syntax_score)
We evaluate various state-of-the-art LLMs in a zero-shot setting. The table below shows the performance breakdown across our four task categories. Click on the column headers to expand detailed results.
| Model | Type | StructEval-T | StructEval-V | Average | ||
|---|---|---|---|---|---|---|
| Generation | Conversion | Generation | Conversion | |||
Performance by Task Type
Challenging Formats (Average Score < 50%)
Even state-of-the-art models struggle with structured output generation. GPT-4o achieves only 76.02% average score, while the best open-source model (Qwen3-4B) lags at 67.04%.
Generation tasks are generally more challenging than conversion tasks. Visual rendering (StructEval-V) proves harder than text-only structures (StructEval-T).
Several formats remain particularly difficult for all models: Text→TOML (35.8%), Text→Mermaid (18.9%), and Matplotlib→TikZ (28.4%) conversions.
Some tasks are effectively solved with scores >90%: JSON, HTML, CSV generation and YAML→JSON, React→HTML conversions show near-perfect performance.
@inproceedings{yue2023mmmu,
title={MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI},
author={Xiang Yue and Yuansheng Ni and Kai Zhang and Tianyu Zheng and Ruoqi Liu and Ge Zhang and Samuel Stevens and Dongfu Jiang and Weiming Ren and Yuxuan Sun and Cong Wei and Botao Yu and Ruibin Yuan and Renliang Sun and Ming Yin and Boyuan Zheng and Zhenzhu Yang and Yibo Liu and Wenhao Huang and Huan Sun and Yu Su and Wenhu Chen},
booktitle={Proceedings of CVPR},
year={2024},
}